DoCoreAI is not just a tool; it's your observability partner to turn AI experiments into enterprise success.
Every AI strategy is unique — that’s why our deployments adapt to your roadmap, aligning with business goals, compliance, and growth.
Proud Member of the
See how DoCoreAI helps CAIOs, CTOs, CIOs, Managers and Developers finally get answers on AI costs, efficiency, and privacy — all in one platform - DoCoreAI.
The Only AI Tool That Optimizes Prompts AND Tracks ROI



For Developers
No more trial-and-error prompt tuning.
Plug-and-play CLI
Instant prompt optimization
Auto-generated charts
Supports OpenAI & Groq
For Managers
Understand how your team uses AI tools.
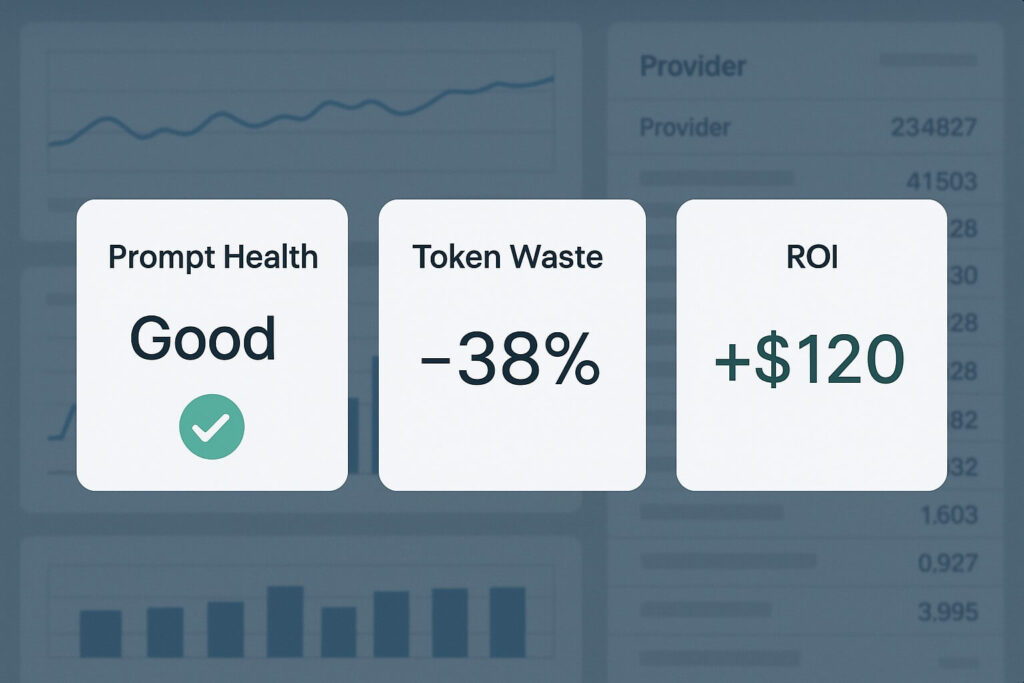
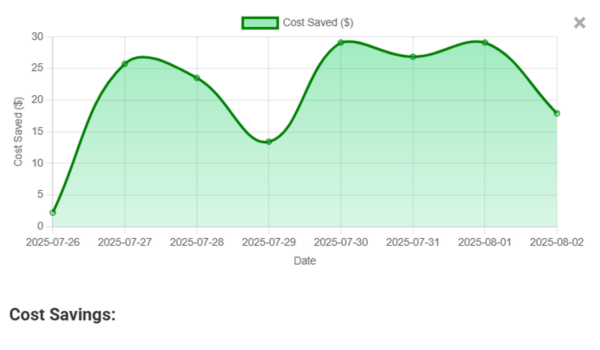
Spot token waste and cost spikes
Track prompt success
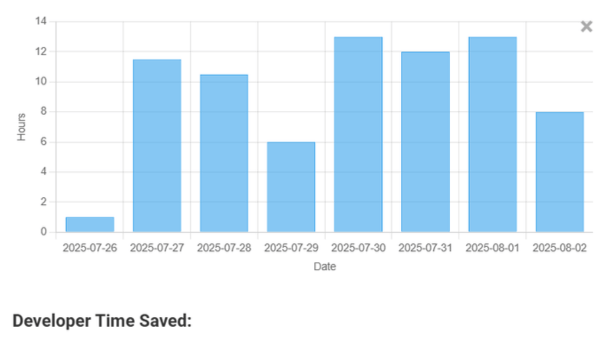
ROI and productivity insights
Zero data retention, developer-safe