Solving the #1 Problem
in Production AI
Privacy-first LLM observability + Intelligent budget control
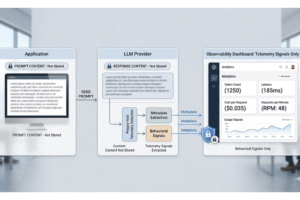
Your team can't answer "Why did our AI bill jump 10× last month?" Traditional APM tools force you to log prompts — a compliance nightmare. Skip logging and you're flying blind. DoCoreAI solves both. Full cost visibility. Zero prompt storage. Budgets that stay on track.
$ pip install docoreai
Works out of the box with
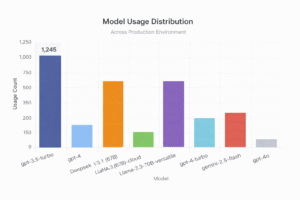
17 months of research.
Real signals. Real momentum.
Built on waste patterns observed across 20+ enterprise AI engagements. Every feature exists because a real team hit a real wall.
From idea to production-ready platform
Identified the privacy vs. visibility gap across 20+ enterprise AI engagements. Started building DoCoreAI to solve it at the infrastructure level.
✓ CompleteCore observability SDK published. LLM cost, token, and latency tracking across OpenAI, Anthropic, and Groq.
✓ Live on PyPIBudget pacing, soft limits, and PII detection engine added. Multi-provider support expanded to include Google Gemini and AWS Bedrock.
✓ Live on PyPIPredictive budget model, A/B testing, drift detection, and auto-retraining shipped. Closed source from v2.0. Selected for Anthropic & AWS Agentic AI Accelerator, Bengaluru 2026.
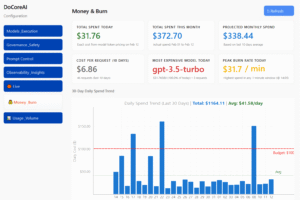
✓ Current versionFull cloud dashboard with real-time spend curves, per-team attribution, and anomaly detection. Enterprise pilot program opens.
⏳ Coming July 2026RBAC, SSO/SAML, and multi-tenant governance for enterprise deployments. SOC2 certification targeted.
⏳ RoadmapLive on PyPI
Install today with
pip install docoreai
.
Full source available at
pypi.org/project/docoreai
.
Python 3.12+ required.
Anthropic & AWS Accelerator
Selected for the Anthropic & AWS Agentic AI Accelerator program, Bengaluru 2026 — validating the architecture and the market opportunity.
Problem validated at scale
The same privacy vs. visibility gap was observed in every single one of 20+ enterprise AI engagements. This is not a niche problem — it is the default state of production AI.
"Before DoCoreAI, I advised 20+ enterprise AI teams on production readiness and governance. The same gap appeared every time — teams could build impressive AI features but couldn't answer basic questions like 'Why did costs spike 400%?' or 'Did customer PII leak through that API call?' AI initiatives died not from technical failure but from lack of visibility and control. DoCoreAI is my answer to that problem."
Global AI observability and monitoring market by 2033, growing at 22.5% CAGR. Privacy-conscious enterprises represent approximately $3.2B of that addressable market.
Of AI-deploying organizations will implement dedicated AI observability tools by 2028 to monitor model performance, bias, and outputs — up from near zero today.
Anthropic & AWS Agentic AI Accelerator · Bengaluru 2026
DoCoreAI was selected for the Anthropic & AWS Agentic AI Accelerator program — recognising its autonomous budget management architecture as a genuine advance in production AI infrastructure.